Scaling real-time: Handling 100k Websocket connections
How I did benchmarks for my Erlang PubSub Carotene
Carotene is a Real-Time Publish/Subscribe server over Websockets. It can be used in different scenarios such as push notifications, chats, collaborative apps, IoT or gaming.
Main features:
- Transport using Websockets with fallback to long-polling.
- Ability to authenticate and authorise users.
- Presence.
- Ability to republish to Redis or RabbitMQ queues.
- Simple interoperability with HTTP based apps.
- Simplicity of use.
In this post we will see how to handle 100k connections in a commodity server (a t2.medium Amazon EC2 instance) and will benchmark other use-case scenarios.
Carotene can scale by adding more nodes to a cluster, so it is interesting to see how much load can a single node handle in a commodity server, such as a t2.medium Amazon EC2 instance (current price $26.28/mo).
Benchmarking on Amazon has some drawbacks, but still it has a major advantage: replicability. It is cheap to reproduce the tests and although some variability in the AWS cloud can be expected, results should be similar. If we were talking here about some high-end machine that we own, our results would depend on the availability of such machine, and they would be harder to replicate.
As usual, if you expect high loads it is useful to run your benchmarks modelling the real scenario you have to deal with. For example, it is very different to have 1000 users in the same channel than to have 1000 users in 1000 channels. In the first case, if every user sends a message per second, 1 million messages will be transmitted by the server (1000 msgs X 1000 subscribers), whereas in the second case only 1000 messages will be served.
100K concurrent connections in a t2.medium instance
The aim of this test was to investigate how resource usage increases with the number of open connections.
To perform this test, we launched a t2.medium instance running Carotene and two additional t2.medium instances that will establish thousands of connections with the Carotene server. Since we are limited to ~64k ports in the client instances (the server has not this limit, since it will use the same port for all the incoming connections), we need several instances launching the tests.
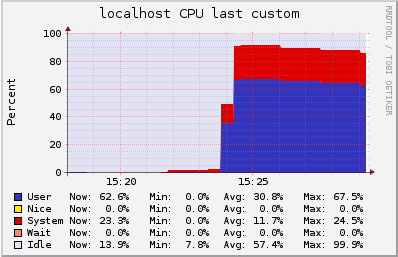
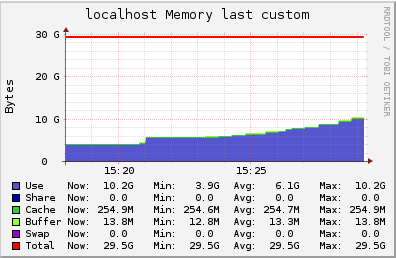
We measured the CPU and memory usage with ganglia:
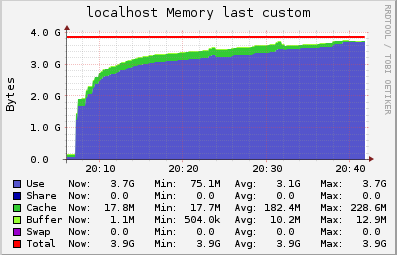
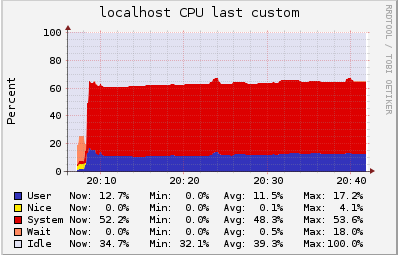
As we can see, we are limited by the amount of RAM in the machine. In this case, a ts.medium instance has a humble amount of 4Gb, but nonetheless it can have 100k open connections.
During this test every client was sending a keep alive message every 20 seconds, and receiving back a pong from the server. So at the peak of 100k users the server was handling 5k messages/sec.
Since this test is limited by the memory, we also launched a test with a r3.xlarge instance, with 32Gb of RAM, but at ~170k concurrent users the bandwidth used for the pings reached 1.1MB/s. Amazon does not warrant a given network bandwidth, so it varies greatly between test runs. In our case, at 1.1MB/s, the instance reached a hard limit, although the RAM and CPU usage was ok. So, although a higher number of connections can be reached in a better machine, in a AWS environment you may be limited by the arbitrary bandwidth available at a given time, and for this reason it may be a better idea to scale horizontally (adding more Carotene nodes) than renting a better instance.
Big channel tests
We also run a number of tests to analyse resource usage in the scenario where many users are subscribed to a single channel, since it is the scenario that poses a bigger challenge to the server. We tried with 500 and 3000 users per channel in two different Amazon instances: a t2.medium and a more powerful m3.2xlarge, to see the implications of a superior platform in resource usage and latency.
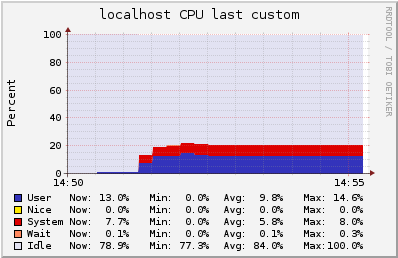
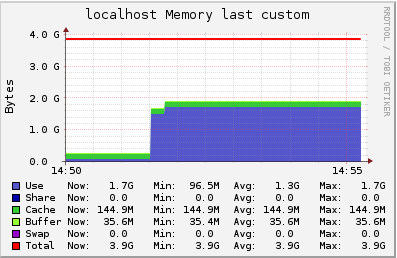
500 users in a single channel in a t2.medium instance
In this test, we have 500 users subscribed to a channel where we publish 30 msgs per second (15k msgs routed/s). Latency observed was lower than 35ms.
3000 users in the same channel in a t2.medium instance
In this test, we have 3000 users subscribed to a channel where we publish 4 msgs per second (12k msgs routed/s). Latency observed was lower than 250ms.
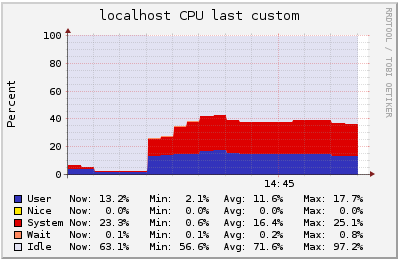
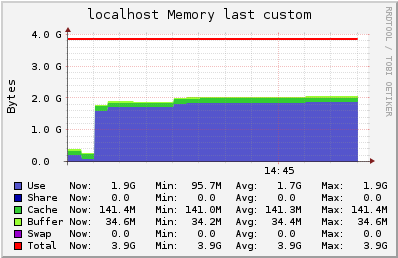
500 users in the single channel in a m3.2xlarge instance
In this test, we have 500 users subscribed to a channel where we publish 250 msgs per second (125k msgs routed/s). Latency observed was lower than 2.8ms, 12 times lower than in the t2.medium instance.
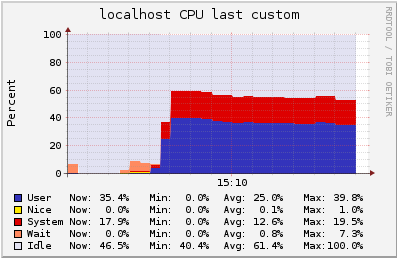
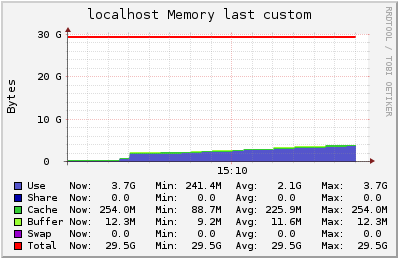
3000 users in the single channel in a m3.2xlarge instance
In this test, we have 3000 users subscribed to a channel where we publish 60 msgs per second (180k msgs routed/s). Latency observed was lower than 15ms, 16 times lower than in the t2.medium instance.
Conclusions
- Memory usage per connection is low, considering that we can fit 100K users in 4GB of RAM.
- More RAM in an Amazon instance does not help (much), since at this number of connections we are also using an amount of bandwidth that can easily fail in the region of what Amazon does not warrant for sure. If the goal is to scale up to much more than 100k connections on a single instance, it may be wise to look for another hosting solution.
- When investing in a better instance, expect lower latency.
- If your goal is to handle as many messages per second as possible, invest in CPU power.
- If your goal is to handle as many simultaneous connections as possible, invest in memory (in a hosting service where bandwidth is not a bottleneck).